Data Operations¶
“May be stories are are just data without a soul” – Brené Brown
This section describes one of the most advanced functionality of the platform, how to upload data into the table. It may be the case that this task is already done, or it is done automatically before you use the workflow. If this is the case, you may skip this section.
The data operations page offers various options to upload data to the table. It follows a brief description of each one of them with a discussion of the merge operation
CSV Files¶
CSV or “comma separated value” files are plain text files in which the first line contains a comma-separated list of column names, and every subsequent line contains the values of these columns for each row. It is a popular format to exchange data that can be represented as a table, and it is for this reason that OnTask allows to upload data in this format.
The functionality assumes that you have such file available in your computer and provides a form to upload it to the platform. Upon uploading, OnTask does a preliminary processing of the data and shows a table with the columns detected in the file and a set of options.

For each column detected in the file, the table includes if it has been detected to be unique, its automatically detected type, a box to select, the name, and an alternative name (to allow column renaming). This step is to allow you to select those columns that are relevant and discard the rest. The platform requires you to choose at least one column with unique values.
Once you selected these values, a new workflow is created with the data from the CSV file.
Merge Operation¶
A merge operation is needed when you want to merge a set of columns with an already existing table. This operation is very common in data science contexts. One of the problems is to specify how the values in the columns are matched with respect to the ones already existing in the table. In other words, each new column has a set of values, but they need to be ordered in the right way so that the information is matched appropriately for every row. The solution for this problem is to include in both the existing table and the new data being merge a unique or key column. These two columns are used to compare the values, identify the matching row, and make sure the right rows are merged.
When uploading a CSV file in a workflow that already contains data, the platform automatically detects it and executes a merge operation. The first step is very similar to a regular update and requires you to select the columns that will be considered for the merge.

However, the difference with this step is that the columns selected will be merged with the existing ones using a given unique column. If no such column is selected the application will not proceed with the merge. As in the case of an initial CSV upload, you main change the names of the columns.
The next step is the most delicate one in a merge. It requires you to identify the unique columns in both the existing data table and the one being uploaded, the criteria to merge the rows, and how to deal when column names collide. We discuss each of these parameters in more detail.
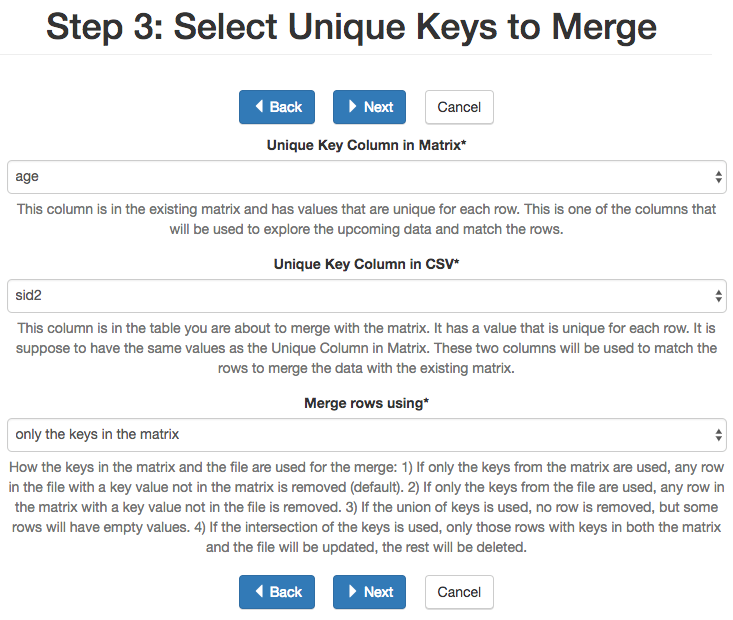
You have to select the pair of unique columns from those in the already existing data and those in the new data about to be merge. These columns are the only choices in the form.
The criteria to merge the rows offers four options:
- Inner
- It will store only the rows for which values in both unique columns are present. Or in other words, any row for which there is no value in either of the key columns will be dropped.
- Outer
- The rows that have only one value in one of the key columns will be considered. You have to be careful with this option because it may produce columns that are no longer unique as a result.
- Left
- Only the rows with a value in the existing table will be considered, the rest will be dropped.
- Right
- Only the rows with a value in the table being uploaded will be considered, the rest will be dropped.
You have to take extra care when performing this operation as it may destroy part of the existing data. In the extreme case, if you try to merge a table with a key column with no values in common with the existing key and you select the inner method, you may end up with an empty table. After selecting these parameters the platform will show you what it will happen with the various columns involved.
